深度學習是一種機器學習 (ML) 的技術,靈感來自於人腦處理資訊的方式。透過深度學習,我們可以自動化一些需要人類智慧的任務,例如圖像識別或語音轉錄等。深度學習演算法運作的方式與人腦相似,模仿大腦中數百萬個相互連接的神經元,它們協同合作來學習和處理資料。在先前的文章中,我們曾提到,一個Logistics Regression可以視為單個神經元,而多個神經元可以組成一個層 (layer)。深度學習正是基於多層神經網路的技術。
深度學習模型是一種經過訓練的電腦程序,能根據一組演算法或預定步驟來執行特定任務。我們可以用它來分析資料並進行各種應用中的預測。這些模型能夠整合來自多個來源的資料,並且實時分析,而無需人為干預。深度學習的效果依賴於大量高品質的訓練資料,資料越準確,模型的預測結果就越精確。
深度學習為許多我們日常使用的 AI 應用提供了基礎技術支援,例如:
此外,深度學習還是許多新興技術的核心,例如自動駕駛和虛擬實境。除此之外,它還被應用於 YouTube 影片標題生成、語音辨識(如電話、逐字稿判斷講者),以及自動駕駛汽車的導航等。
我們可以通過把多個Logistics Regression前後連接在一起,把一個Logistics Regression稱爲Nueron,整個就叫做一個Nueral Network。我們可以用不同的方法來連接Nueral Network,就可以得到不同的Structure。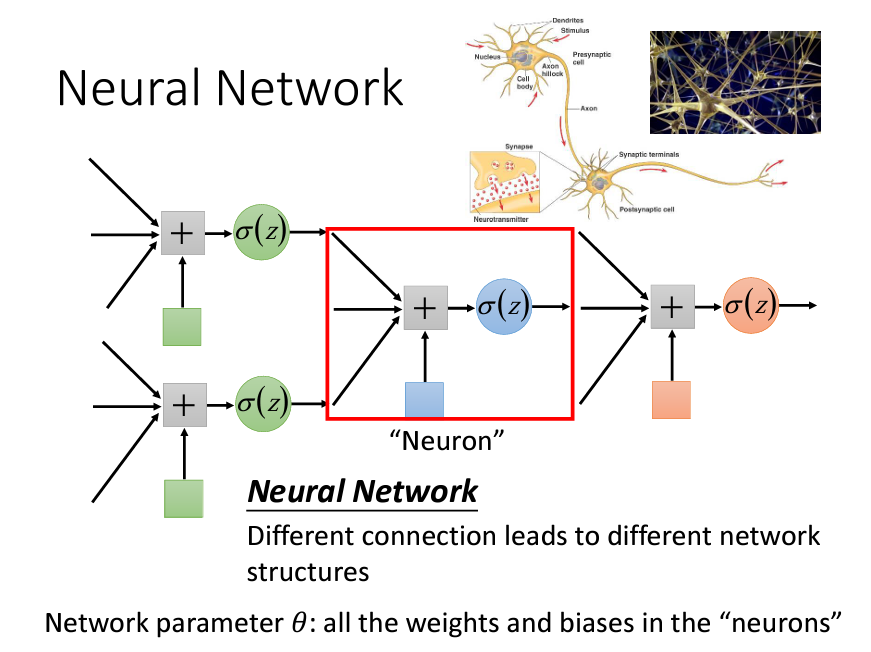
至於要怎麽把這些Nueral Network接起來呢?最常見的方式是Fully Connect Feedforward Network。
Fully Connect指的是網絡中的每一層的每一個節點(神經元)都與下一層的每一個節點相連。每個連接都有一個權重,神經元通過這些權重將輸入信息傳遞到下一層。這種全連接結構確保信息能夠在層與層之間完全傳遞,但也會導致模型參數(權重數量)增多,增加了計算覆雜度。而Feedforward意味著數據在網絡中是單向流動的,從輸入層經過隱藏層傳遞到輸出層。數據不會回傳,也不會在網絡中循環。因此,前饋網絡的計算過程是順序的,從輸入開始,逐步向前傳遞,直到產生輸出結果。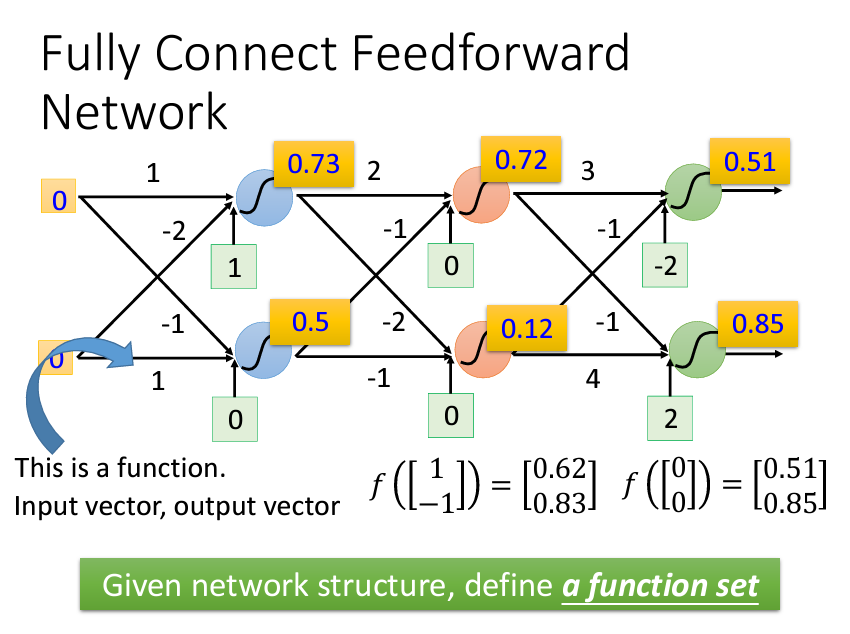
在第一層的Layer前面,我們需要一組vector作爲輸入,在輸出端的時候,我們也會輸出一組vector,我們會將輸入的那一層成爲input layer,輸出成爲output layer: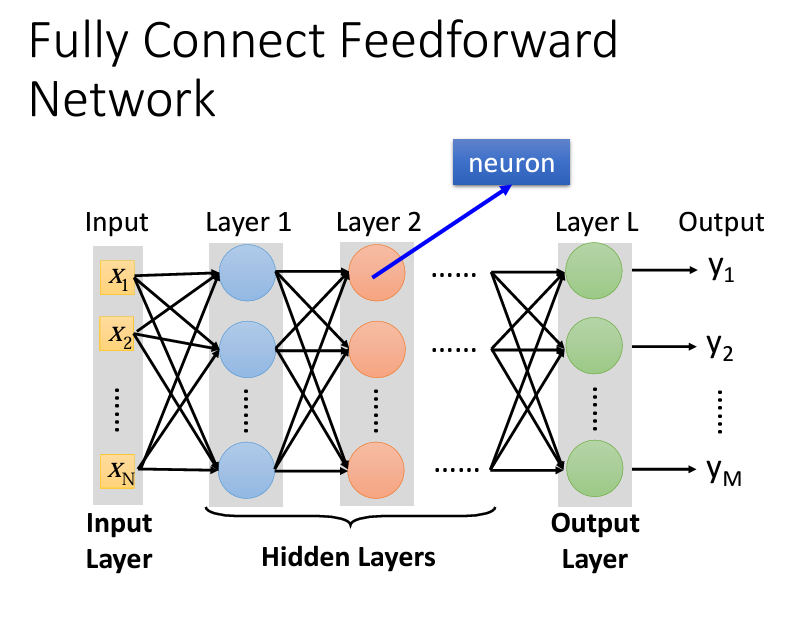
Network的運算通常是以Matrix Operation來表示。我們知道一個neuron的公式是y=wx*b,以輸入層爲例,輸入層是一組vector(x),會乘上一組Matrix(w)加上一組bias(b),這些都是矩陣的運算,如下圖: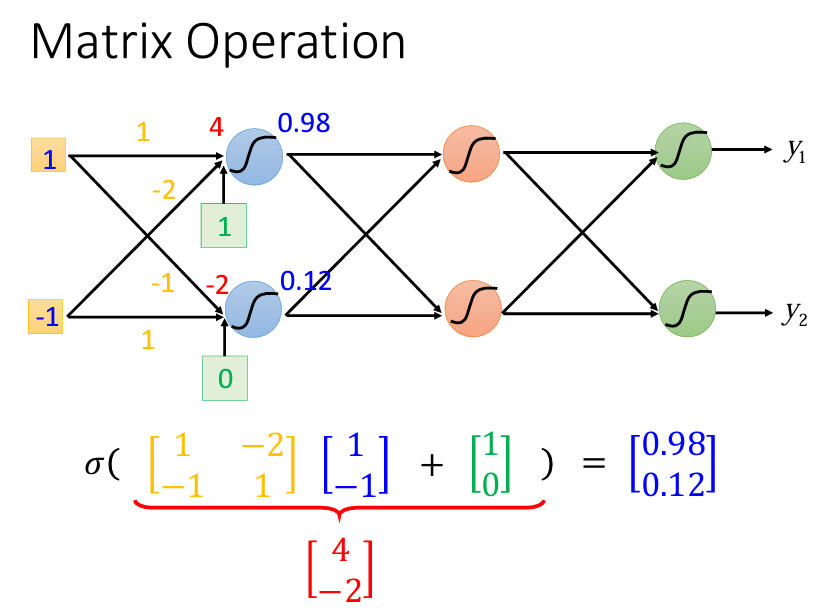
如果我們再把算出來的vector放到我們的激活函數sigma内,再把這個經過激活函數轉換後的vector當作下一層的輸出: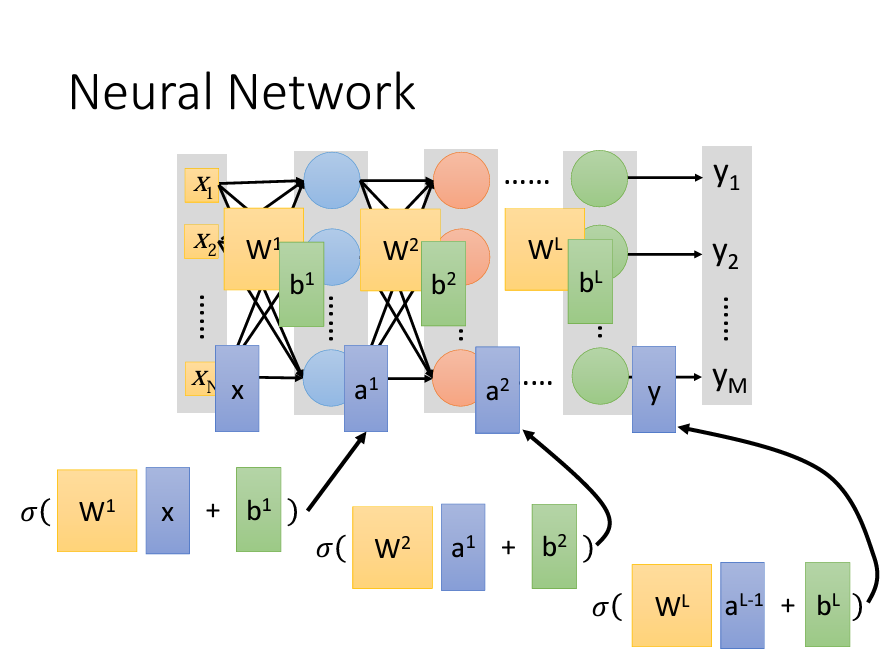
所以其實一整個Nueral Network的運算就是一連串的Matrix Operation的運算。
在整個Nueral Network裏面,我們可能會有很多的hidden layer,我們可以將hidden layer看作是feature extractor,就是説我們之前在做機器學習的時候,我們需要人來做特徵工程,但是現在我們的hidden layer會自動幫我們做這件事。
以上的内容大部分來自於臺大教授李宏毅:鏈接,我只是把他的影片寫成了筆記。


 iThome鐵人賽
iThome鐵人賽